Background
The Challenge in System Description
Building and managing AI/HPC systems today feels a bit like untangling a giant ball of yarn.
Modern AI systems integrate complex, heterogeneous components like compute, memory, and storage, all connected by diverse scale-up and scale-out interconnect topologies. Think of the intricate networks in a large AI factory – it's a mix of different technologies and topologies."
But, a clear, standardized way to describe this overall infrastructure is missing. This isn't just a technical challenge; it creates real problems for everyone involved. It makes it incredibly difficult to benchmark, to simulate 'what-if' scenarios, or even to manage these systems efficiently. The result? Significant operational overhead, often low hardware utilization, and a lot of frustration for those trying to get these powerful systems to perform."
We believe capturing this diversity, this inherent complexity, in a structured way is the first step to reasoning with it."
Why Standardize?
Why go through all this effort? Because we want to move beyond just 'making it work' to truly 'optimizing it.' Our goal is to transform massive AI clusters from monolithic problems into structured, analyzable systems. When you have a standardized description, you can feed that information directly into your tools – your simulators, your emulators, even your deployment systems.
This means better predictions about how your AI workloads will perform before you even run them. And it opens the door for something really powerful when doing vertical co-design. It's about making sure your hardware and software are talking to each other, working together seamlessly, from the lowest-level chip to the highest-level application. This ensures accurate performance prediction and validates AI workloads pre-deployment.
This isn't just about efficiency; it's about building performant, reliable, and cost-effective AI infrastructure that can keep up with the demands of tomorrow and experimenting with what-if scenarios. Let's look at a concrete example.
From Schema to Simulation/Emulation
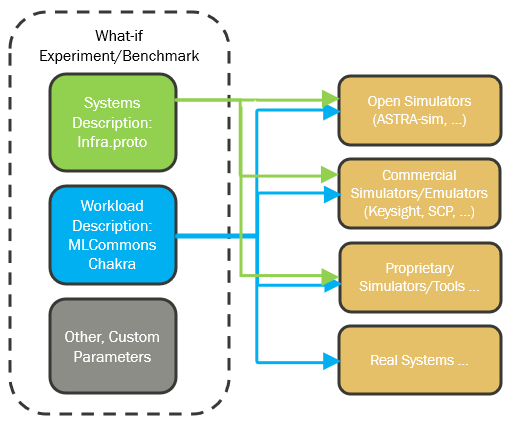
So, here's how we put it all together. The challenge is that these complex AI systems are incredibly difficult to model accurately. Say you have a particular infrastructure benchmark like looking at how collective libraries will perform given different design choices, A vs. B.
Our solution involves combining two key pieces: our InfraGraph schema, which precisely defines the cluster's topology, and the MLCommons Chakra workload traces, which capture the actual behavior of AI applications.
Together, these standardized inputs feed directly into powerful simulators like AstraSim. This isn't just theoretical; it's a working proof point. It allows us to run detailed 'what-if' analyses, explore different design choices of how a cluster is composed together, and truly understand performance trade-offs.
This capability effectively democratizes the evaluation of complex AI systems, putting powerful analysis tools into more hands.
- infrastructure schema + MLCommons Chakra
- standardized
infrastructure schemadefines system of systems chakraprovides workload traces
- standardized
- topology input for various tools (ASTRA-Sim)
- enabled
what-ifanalysis, design choices - democratizes complex system evaluation
- an
infrastructure schemais a flexible starting point today